** Checkout our latest work "How hard are computer vision datasets? Calibrating dataset difficulty to viewing time".
See the download page for instructions on how to get ObjectNet
What is ObjectNet?
- A new kind of vision dataset borrowing the idea of controls from other areas of science.
- No training set, only a test set! Put your vision system through its paces.
- Collected to intentionally show objects from new viewpoints on new backgrounds.
- 50,000 image test set, same as ImageNet, with controls for rotation, background, and viewpoint.
- 313 object classes with 113 overlapping ImageNet
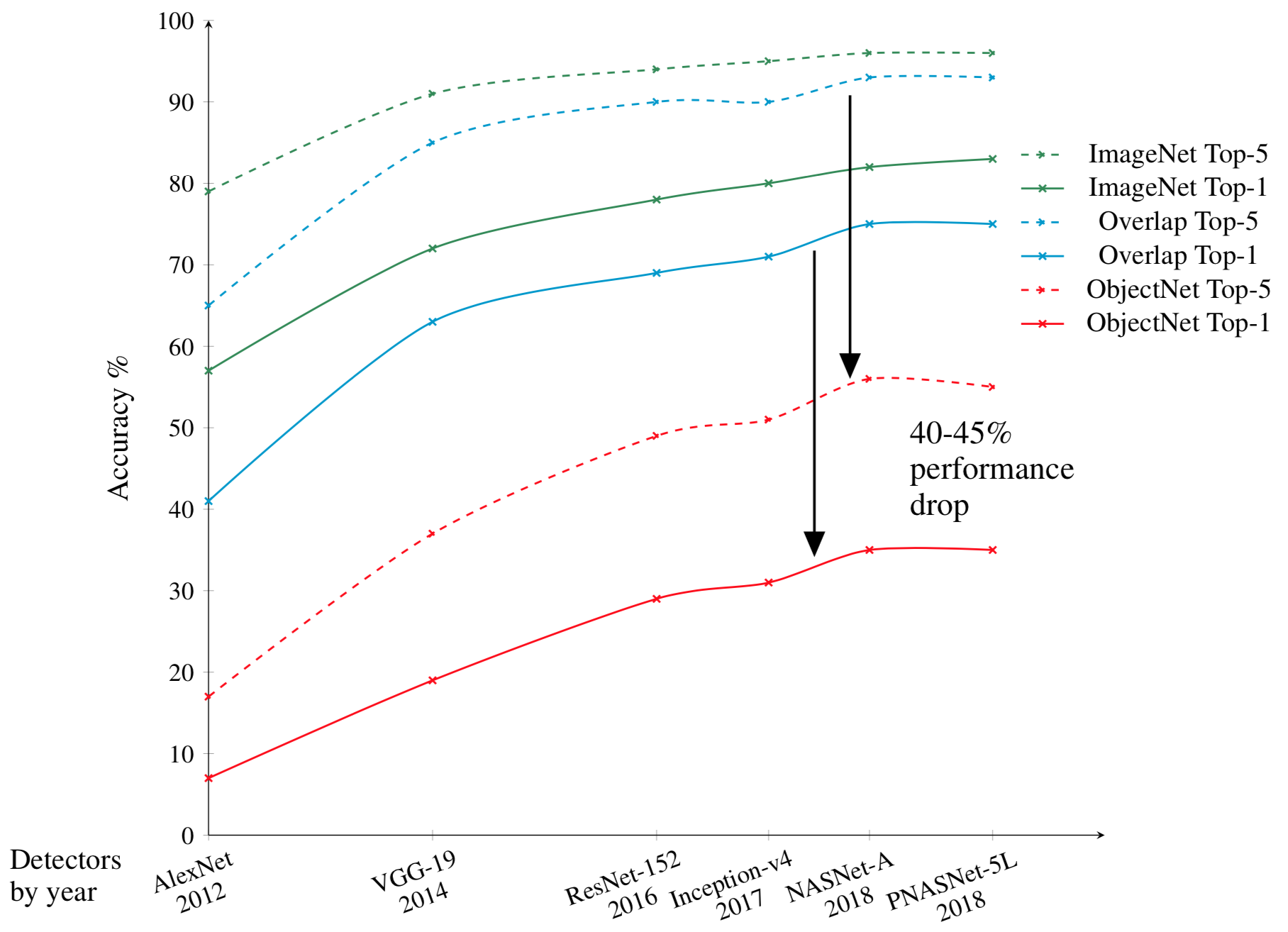
- Large performance drop, what you can expect from vision systems in the real world!
- Robust to fine-tuning and a very difficult transfer learning problem
Controls for biases increase variation

Easy for humans, hard for machines
Ready to help develop the next generation of object recognition algorithms that have robustness, bias, and safety in mind. Controls can remove bias from other datasets machine learning, not just vision.
ObjectNet is a large real-world test set for object recognition with control where object backgrounds, rotations, and imaging viewpoints are random.
Most scientific experiments have controls, confounds which are removed from the data, to ensure that subjects cannot perform a task by exploiting trivial correlations in the data. Historically, large machine learning and computer vision datasets have lacked such controls. This has resulted in models that must be fine-tuned for new datasets and perform better on datasets than in real-world applications. When tested on ObjectNet, object detectors show a 40-45% drop in performance, with respect to their performance on other benchmarks, due to the controls for biases. Controls make ObjectNet robust to fine-tuning showing only small performance increases.
We develop a highly automated platform that enables gathering datasets with controls by crowdsourcing image capturing and annotation. ObjectNet is the same size as the ImageNet test set (50,000 images), and by design does not come paired with a training set in order to encourage generalization. The dataset is both easier than ImageNet – objects are largely centered and unoccluded – and harder, due to the controls. Although we focus on object recognition here, data with controls can be gathered at scale using automated tools throughout machine learning to generate datasets that exercise models in new ways thus providing valuable feedback to researchers. This work opens up new avenues for research in generalizable, robust, and more human-like computer vision and in creating datasets where results are predictive of real-world performance.