Minimum required viewing time dataset
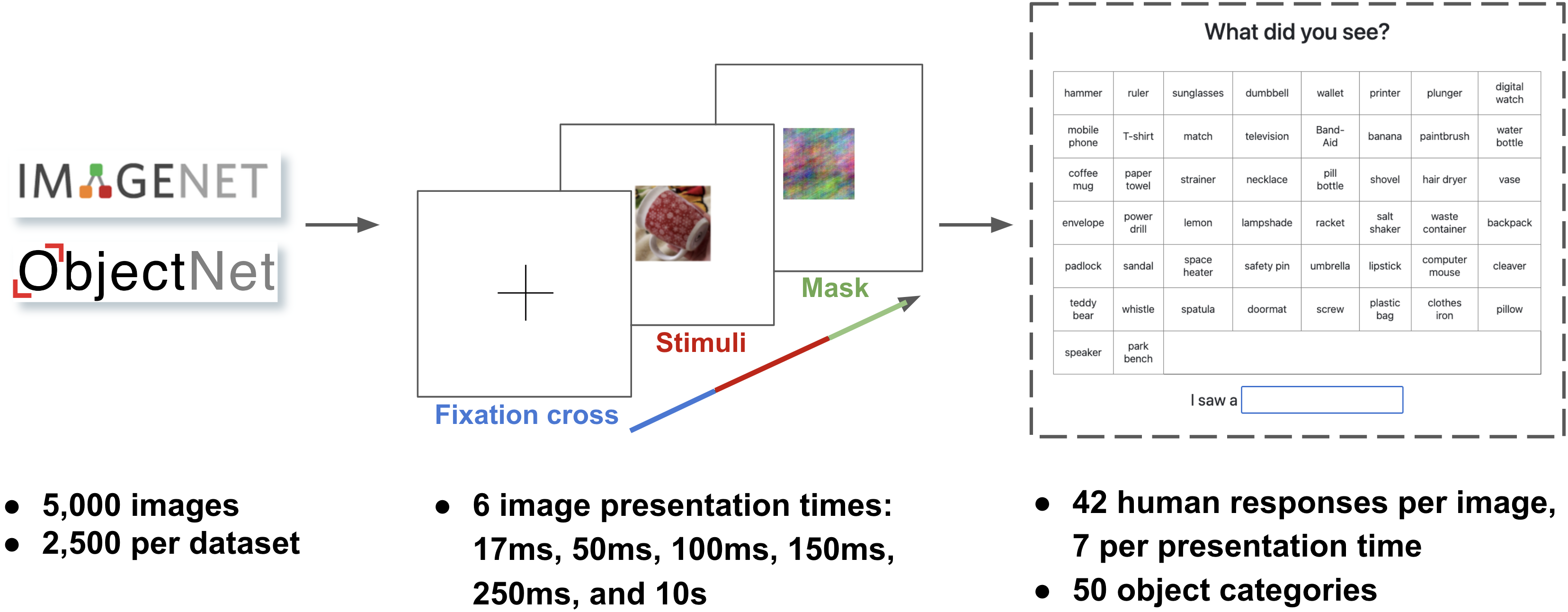
A dataset of 200,382 human object recognition judgments as a function of viewing time for 4,771 images from ImageNet and ObjectNet. The human judgments allow us to calculate an image-level metric for recognition difficulty based on minimum exposure in milliseconds that humans needed to reliably classify an image correctly. This allows us to explore dataset difficulty distributions and model performance as a function of recognition difficulty. These results indicate that object recognition datasets, are skewed toward easy examples and are the first steps toward developing tools for shaping datasets as they are being gathered to focus them on filling out the missing class of hard examples. Read more in our upcoming publication!
Examples of increasing recognition difficulty

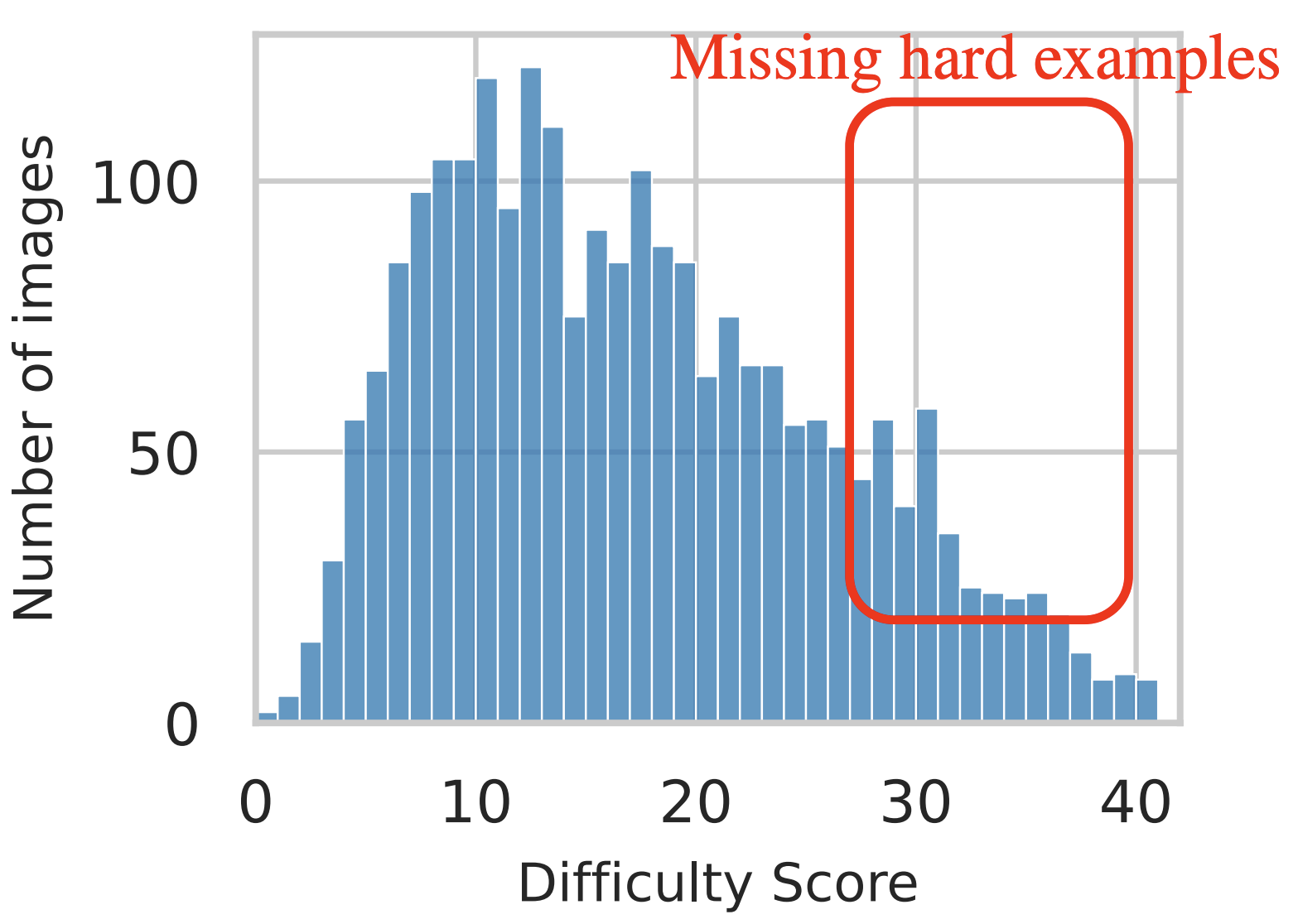
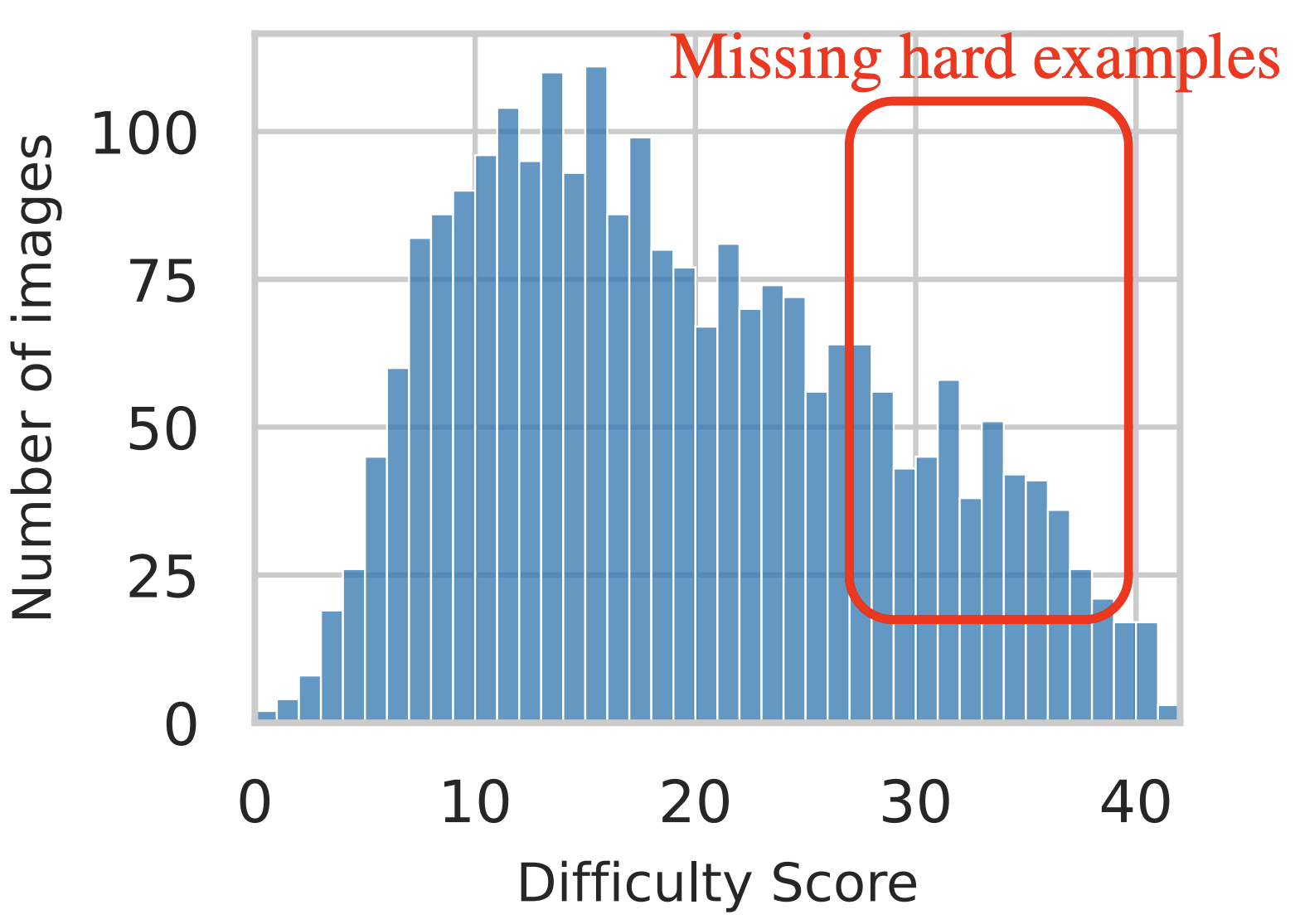
Modern datasets are skewed toward easy images
Our difficulty metric indicates that object recognition datasets are skewed toward easy images. Even ObjectNet which was deliberately collected to control for biases found in other datasets has a remarkably similar difficulty distribution as ImageNet. Without consciously collecting difficulty images, datasets will continue to misrepresent the recognition abilities demonstrated by humans in the real world.
 |
 |
Ensuring representation of difficult images is important as models not only perform significantly worse on hard images, but our results show that performance drops as a result of distribution shift are exacerbated by image difficulty. Surprisingly, increasing the capacity of models in most model families makes no progress toward reversing this trend---although OpenAI's CLIP model demonstrates high robustness. There are likely other phenomena in addition to distribution shift that demonstrate a similar dependence on image difficulty. If benchmarks continue to undersample hard images, misleading model performance will mask these issues. See our paper for more details.
Experiment Overview